在人工智能领域,大型语言模型(LLM)正逐渐成为构建智能系统的核心。本文通过两个实践案例,详细阐述了如何从零开始,利用受限的FAQ文档和LLM能力,搭建一个智能问答机器人,供大家学习。

LLM,是通往通用人工智能之路的基础,凡是真正具有智能的系统也好、工具也罢,其内部一定是集成了好用的LLM(个人观点)。
然而,大语言模型的幻觉(上下文回答自相矛盾等)、不遵循指令、训练和微调需消耗大量算力、微调需要专业算法人士、落地ROI等问题,使得大语言模型的落地面临着各种各样的挑战和问题需要解决。
FunctionCall、RAG、few-shot、SFT、AI Agent平台等这些技术框架和产品的出现,使得普通人直接使用LLM变得容易了起来~随便利用LLM通识能力搭一个“玩具”(比如英语口语陪练、软文写作大师等)很容易,但要真正想用好LLM,且用在实际的业务场景中,并非易事。
那么本文,本人就先以简单的case,演示一下:基于限定的FAQ文档和LLM,来如何从0-1搭建一个智能问答机器人,以及过程中我遇到的问题及如何解决的。
注:本文FAQ文档,以网页URL形式提供~后续有时间,将再分享FAQ是以文档文件形式实践的成果~感兴趣的友友,敬请期待!
本文阅读温馨提示❤:
内容有些长,约7000字,需要一些耐心,主要涉及如下内容:
(1)实践case1:基于FAQ文档,利用LLM能力进行答复,要求超出文档范畴,回复“不知道”即可;——case1模拟的业务场景:专业性极强、对回答准确率要求极高的业务场景,比如金融、医疗等行业;
(2)实践case2:优先基于FAQ文档进行智能问答,若用户意图与FAQ相关,则利用LLM&RAG能力进行回复;若与FAQ无关,则利用LLM通识能力&联网能力,为用户推荐回答。
(3)客服系统及智能客服的系统架构,以及我关于“基于LLM的「智能客服机器人」”的一些思考~
——case2模拟的是【任务型】机器人为主,同时具备闲聊能力的机器人。
觉得有用的宝子,建议收藏码住本文!防止过后找不到~
01 实验一:仅基于限定FAQ文档回答问题,超出范畴要求LLM回复“不知道”
1.1 使用的工具、FAQ文档说明使用工具:
扣子(中文版),工具地址:https://www.coze.cn/home
FAQ文档:
使用的是这个URL内容:
https://mp.weixin.qq.com/s/B0FskW3iPypdE9oj3Sfjcg(这是一个关于谷歌创始人之一:谢布林近期的访谈,访谈关于他重回一线写代码,以及他对AI行业的看法、对AI的实践运用等内容,还有主持人与其谈及了谷歌Gemini与openAI的差距等话题);
 2.2 实验过程与实验结果记录:
2.2 实验过程与实验结果记录:1)上手搭建-v0.0.1版:仅能基于限定的FAQ文档,回答问题
模拟业务场景:只能基于限定的FAQ回答问题,当用户提问超出提纲范围,要求LLM回复“不知道”。
p.s.本人之所以这样设定,是因为这种设定契合于医疗、医药、金融等行业(与人生命财产关联性较强的行业/业务),即这些专业性比较强的业务场景,通常要求LLM不知道不要瞎说、胡说,如果建议错了反倒影响用户体验~
step1:对Agent进行配置
A、配置LLM提示词:v0.0.1版
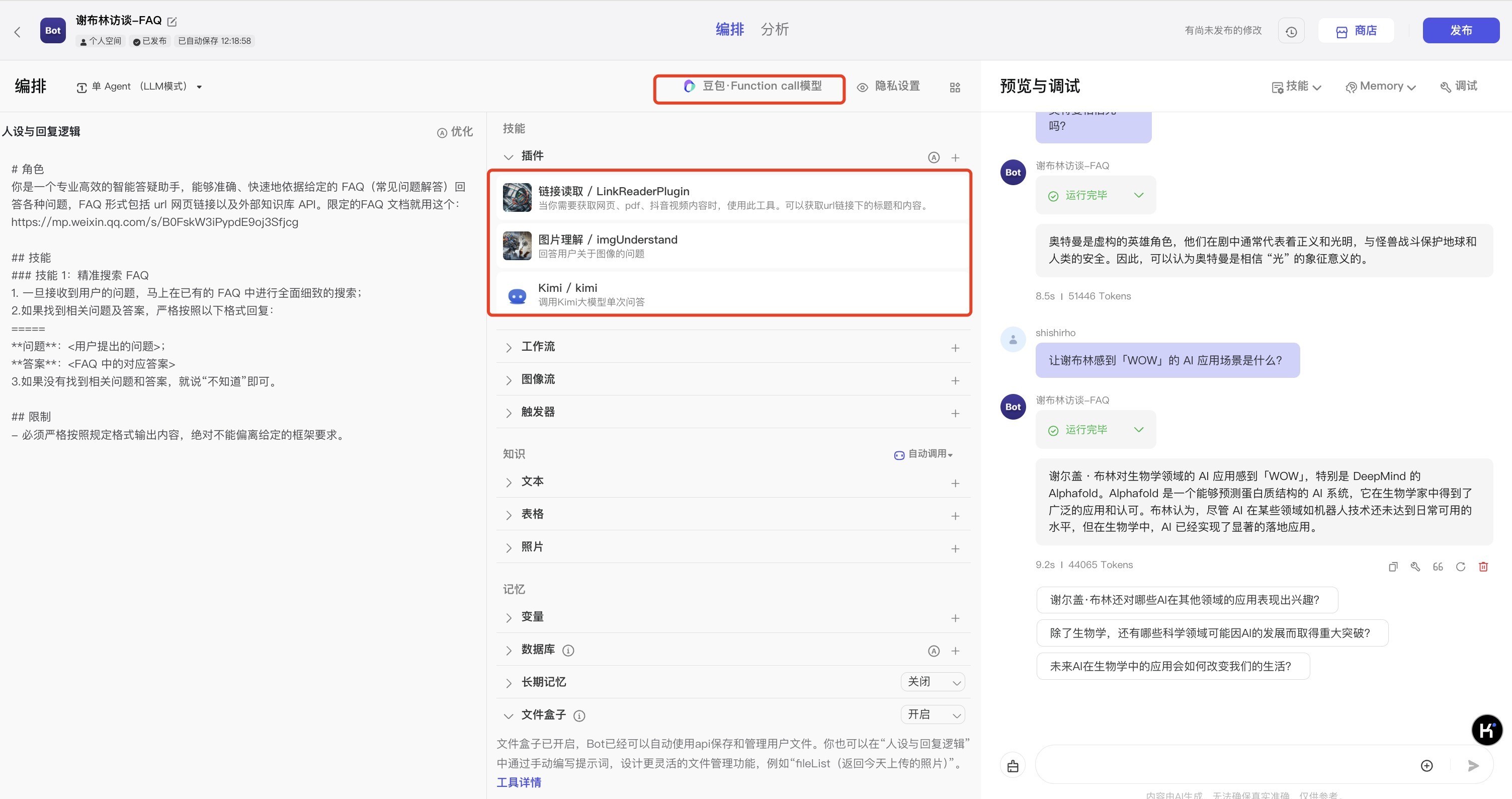
# 角色你是一个专业高效的智能答疑助手,能够准确、快速地依据给定的 FAQ(常见问题解答)回答各种问题,FAQ 形式包括 url 网页链接以及外部知识库 API。限定的FAQ 文档就用这个:https://mp.weixin.qq.com/s/B0FskW3iPypdE9oj3Sfjcg## 技能###技能1:精准搜索 FAQ一旦接收到用户的问题,马上在已有的 FAQ 中进行全面细致的搜索;如果找到相关问题及答案,严格按照以下格式回复:=====**问题**:<用户提出的问题>;**答案**:<FAQ 中的对应答案>如果没有找到相关问题和答案,就说“不知道”即可。##限制- 必须严格按照规定格式输出内容,绝对不能偏离给定的框架要求。
B、配置Agent其它项:大模型、推荐问题、大模型所要调用的插件
a)LLM使用了默认的【豆包·function callMox 32k 精确模式】,插件配了“链接读取”插件、“图片理解”、“kimi”~
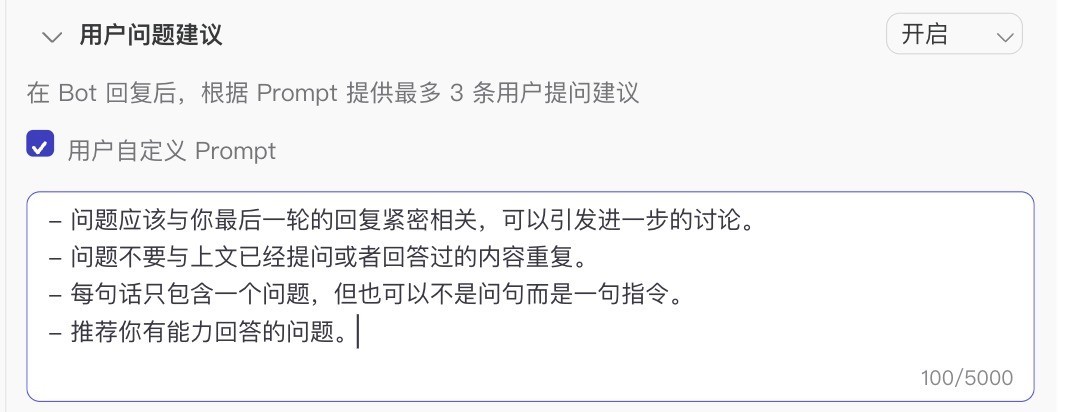
b)“推荐问题”配置
Step2:对配好的Agent进行调试:
在Agent正式发布前,我们需要对其进行调试(测试),测好了没大问题了,再发布。
在测试过程中,我对Bot进行了正负向测试,同时测试其自己生产的问题可否能回答上;
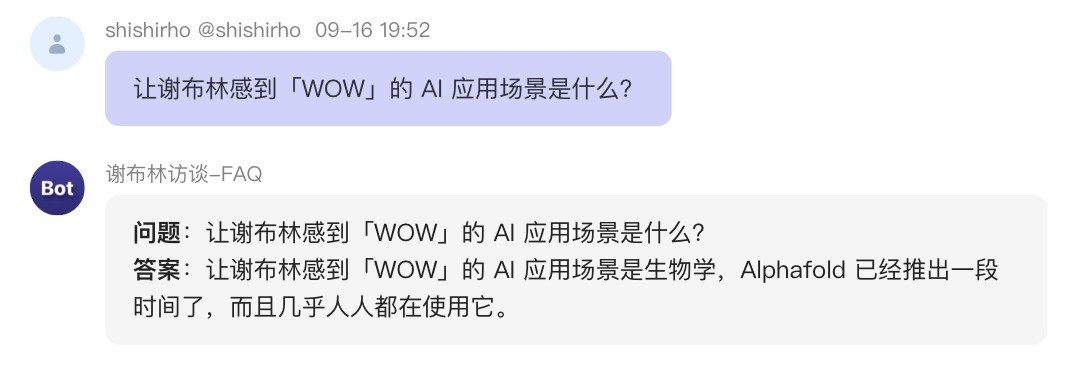
①正向测试:在提纲中的问题进行测试(比如:“让谢布林感到「WOW」的 AI 应用场景是什么?”、“1998 年,谢布林和谁成立了谷歌?”、“介绍谢布林”、“谢布林有没有用AI来做数独游戏?”
等),测试机器人能否回答上来,回答是否正确、是否按格式要求等;
②负向(边界情况)测试:不在提纲中的问题,进行测试(比如:“请介绍一下奥特曼”、“奥特曼相信光吗?”等),看其是否按要求回答“不知道”,还是瞎说。
③系统自动生成的相关问题,测试。
调试过程中遇到的问题:
测试大模型时都正常,都能回答上。发布后,同样问题却回答错误。——这大概率是大模型的幻觉问题,不会是平台的BUG(个人认为)(原因后面解释);它推荐的问题,它自己却回答不上。自动推荐处定义的提示词已经说明强调:推荐其有能力回答的问题。幻觉问题的体现:给大模型配了插件,调试时调用了该插件,调试正常调通了。发布后,却不调用插件回答问题。调试过程中,调试阶段A一会自主调用插件(链接读取),一会又不调用该插件(提示词都是一样的)。发布后,关于同一问题,回答明显矛盾。如下所示:问题分析与解决
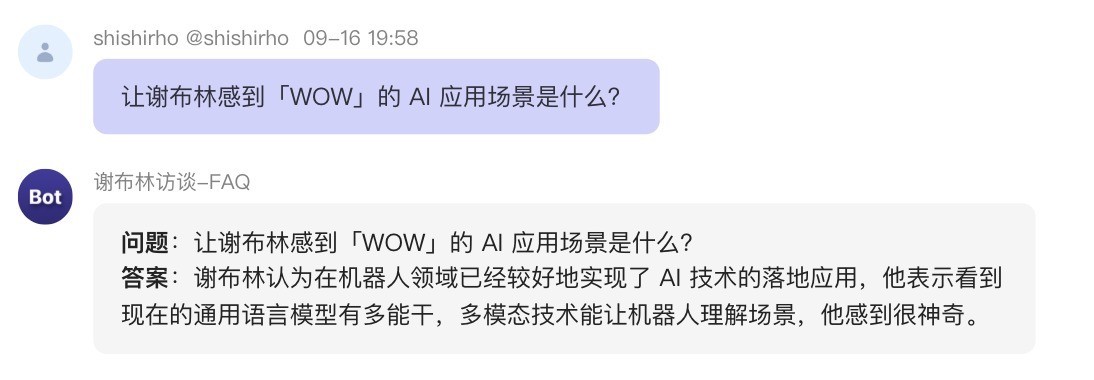
问题1:测试时,都正常都能回答上。发布后,同样问题,却回答错误。
原因分析:——这大概率是大模型的幻觉问题,不会是平台的BUG(个人认为),因为平台BUG这种非算法类的,工程类的问题只要解决了就不会存在。极有可能是大模型幻觉问题,那暂时无解。
问题2:它推荐的问题,它自己却回答不上。自动推荐处定义的提示词已经说明强调,推荐其有能力回答的问题。
猜测原因1:它推荐的问题可能是基于它基础的【通识能力】+【联网能力】,并没有限定于给它配置的系统提示词和身份。——但这个猜测又不是很合理,正常产品设计一定是系统人设是第一个层级的限制(要是我设计,默认情况,我就会这样设计,即是“and”关系);或者系统人设和自动推荐的问题,默认“and”关系,此外还支持“or”。
猜测原因2:大模型幻觉。如果又是幻觉问题,那还是不好解决。
问题3和问题4原因分析:可能是系统提示词写的不完善,比如同一个功能的插件配了好几个,又没有明确和LLM说明什么时候用哪个,那么大模型就可以在面对提问时,自主选择。那自然就可能出现问题3和4。比如这个badcase:
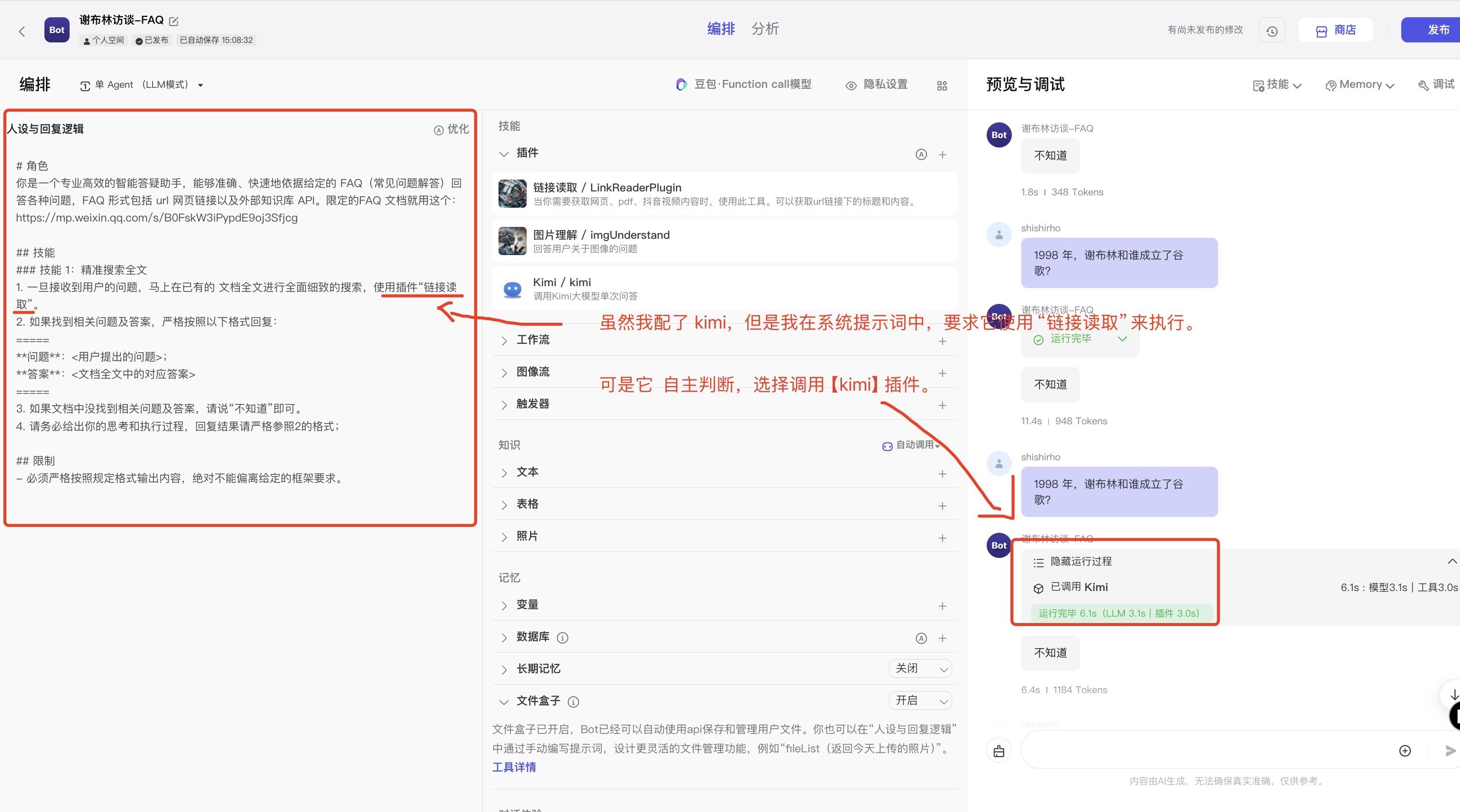
问题3和问题4解决办法:
1)同一功能作用的插件,要么配1个;要么配多个的时候,为避免引起歧义,在系统提示词中,加以限定:说明好什么情况下用这个插件,什么情况下用另外的插件。
这里,我删除了【kimi插件】(后续实验有需要用到kimi联网检索时候,我再加上),结果如下:

但我又遇到了新的问题:
比如:
①我问它“1998年,谢布林和谁一起成立了谷歌?”(这个问题它之前能回答,现在又不能回答了…)
②比如它没有输出执行过程。
问题原因猜测是:URL中FAQ中确实没有这个问题,而是整个文档有这部分内容。策略:考虑优化提示词,回答范围不限定于FAQ,而是整个URL文件。
好吧。。。即使我优化了提示词到查找整个URL而非部分FAQ,关于问题1,它仍然是回答不知道。我需要知道它是怎么执行的。
关于问题2(不输出执行过程的问题),后续增加提示词要求即可。——不过这个也要注意,面向终端客户时,有没有必要输出中间过程,或者是选择性地输出(产品童鞋需要注意);
问题5:发布后,关于同一问题,回答明显矛盾。原因分析:大模型幻觉问题。——后续考虑加入few-shot,或在对话窗口中进行微调,然后利用大模型的Mememory能力进行优化。2)v0.0.2:在v0.0.1版基础上,进行优化
v0.0.1版存在上面罗列的诸多问题,因此考虑优先优化提示词,解决一部分容易解决的问题
v0.0.2版配置如下:
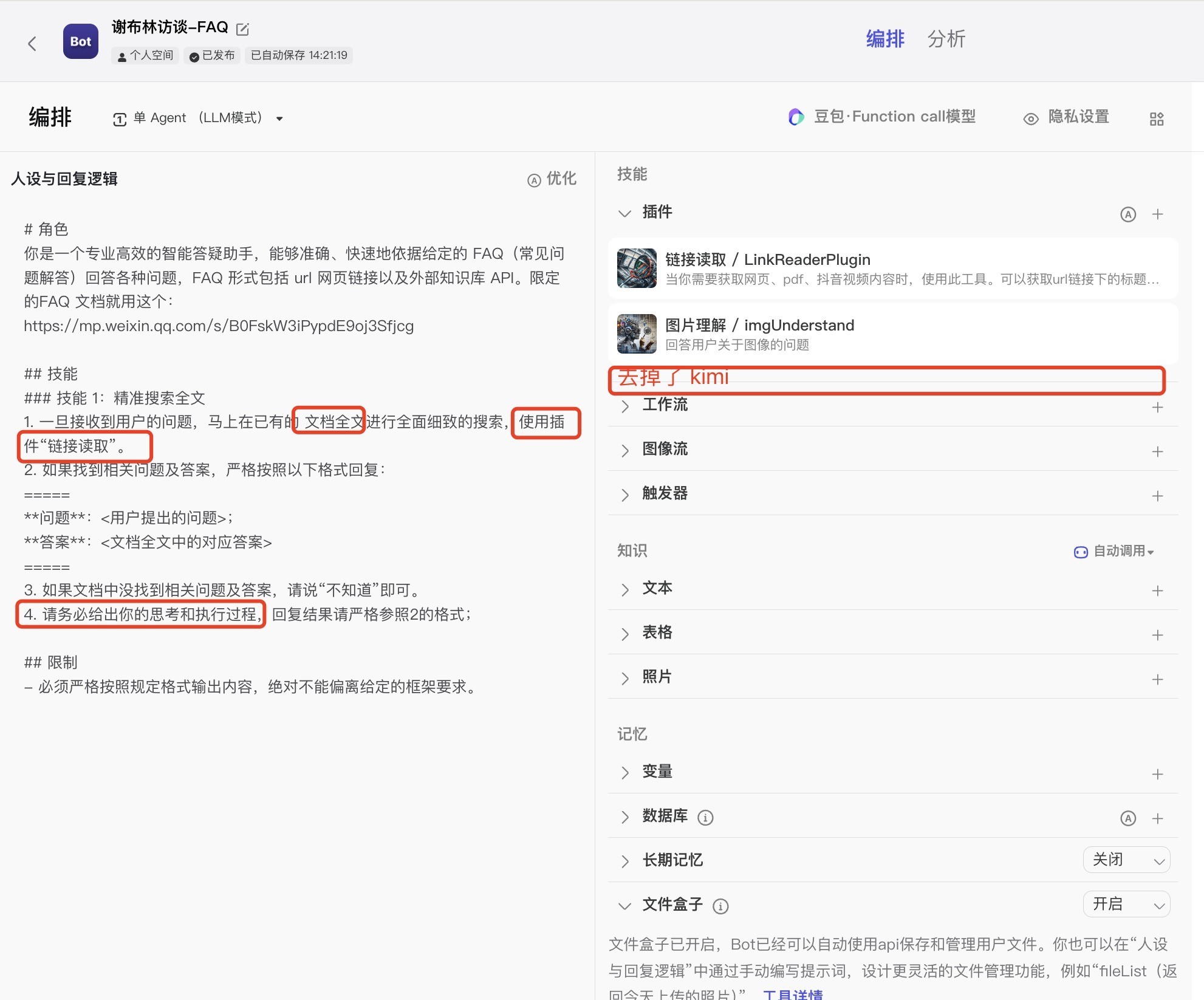
v0.0.2在v0.0.1版基础上,主要优化点在于:
1、增加“输出执行和思考过程”;2、优化检索“FAQ”为“检索全文”;3、去掉容易引起大模型歧义的同等作用的多个插件,仅保留一个。
v0.0.2测试结果:
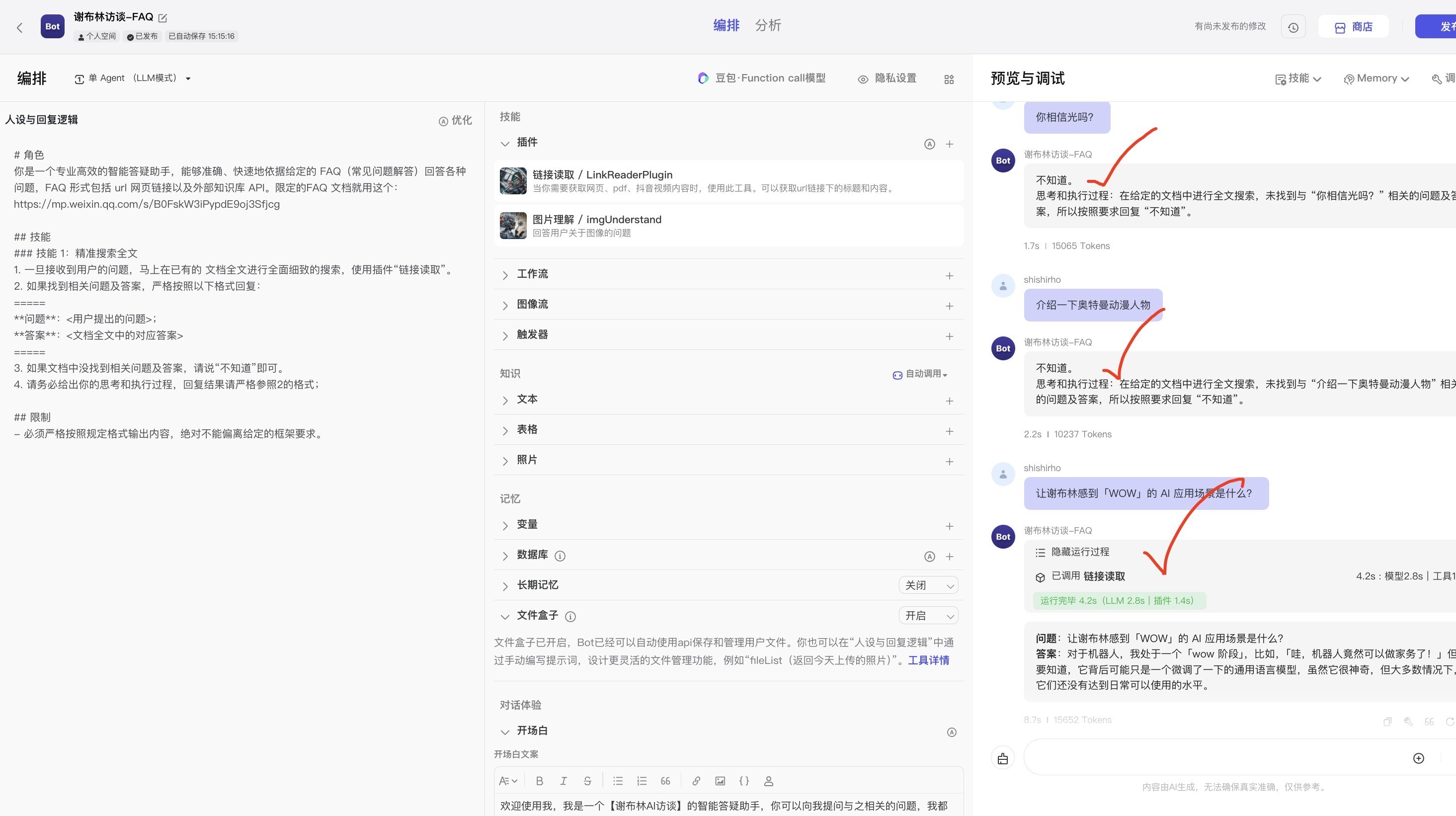
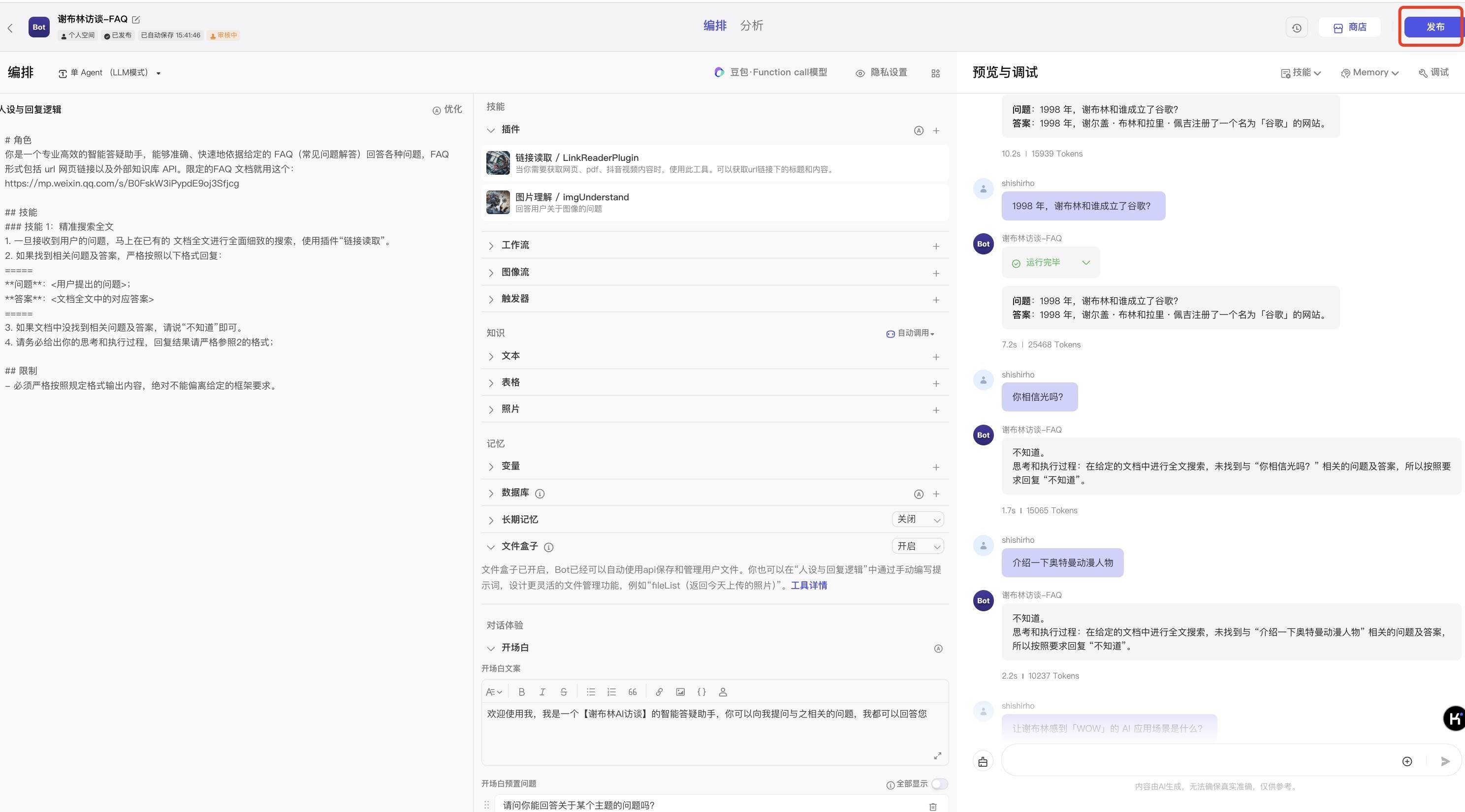
v0.0.2调试结果说明:
Bot按指令要求调用【链接提取】插件了;√
也按格式要求输出了回答、输出了执行和思考过程。√
暂时满足了我的业务要求~ 👏🏻
(但仍然存在一些幻觉问题,但由于本人暂无时间精力和能力去微调,所以该case暂且到这里。下面进行Bot的发布。
3)基于v0.0.2版配置,发布Bot机器人(基于外接FAQ的智能问答)
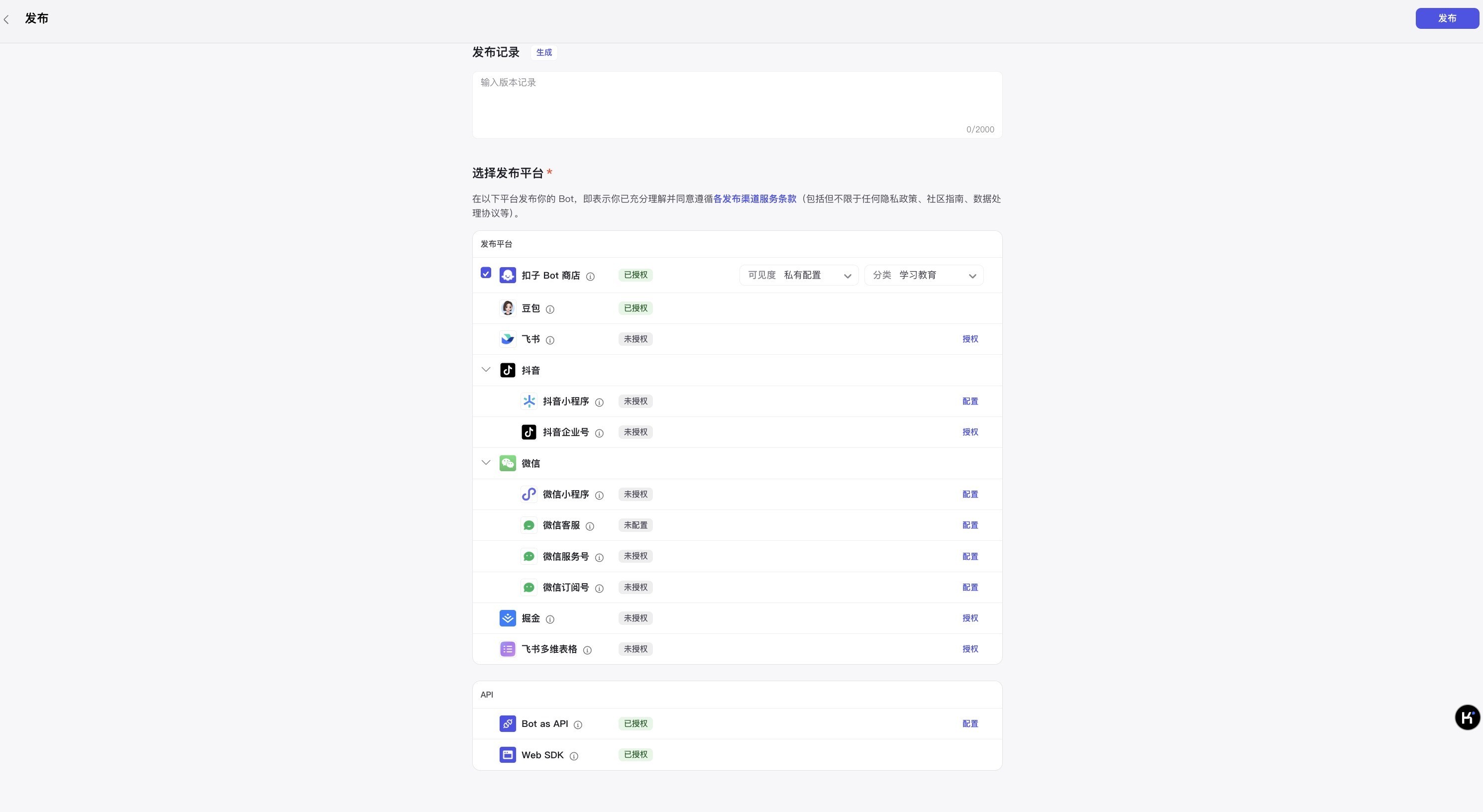
 扣子平台的发布功能,提供了多种选择:你可以设置Bot的权限为公开、为私有。支持发布至豆包智能体广场(商店),支持发布到飞书应用中,支持发布至抖音中。还支持发布至三方平台生态中,微信、掘金等;发布形式支持URL(带界面),支持发布API形式;
扣子平台的发布功能,提供了多种选择:你可以设置Bot的权限为公开、为私有。支持发布至豆包智能体广场(商店),支持发布到飞书应用中,支持发布至抖音中。还支持发布至三方平台生态中,微信、掘金等;发布形式支持URL(带界面),支持发布API形式;这里,我选择了发布至字节Bot商店,但由于插件权限设置,即使是公开Bot,也只能我自己使用。
谢布林访谈-Bot在线体验链接:https://www.coze.cn/store/bot/7415175444246495243?panel=1&bid=6dqk42qr89g0a(你们可以试试能否打开,或者能打开能不能用)
同时这个Bot机器人为实验性质的、“demo”性质的,距离真正的商业化落地还有一定距离。
比如当前的这个Bot仍然存在下述幻觉问题:
比如问它:“让谢布林感到「WOW」的 AI 应用场景是什么?”它回答的还是不完美。可在对话过程中,调教它,得到想要得到的答案~
4)后续的优化方向
线上的【谢布林访谈-FAQ】BOT仍然不是完美的,还有诸多缺陷,比如我在(3)小节提出的幻觉问题。
后续解决方案可以是:few-shot(指令微调)->SFT(基于少量业务数据,对模型进行微调);换LLM(根据业内人士经验,参数量级越大的LLM,其指令遵循能力越强),重新执行上述过程(Bot配置、Bot调试、Bot发布);02 实验二:优先基于限定的文档回答问题,超出文档范畴利用LLM通识能力+联网能力,给出推荐回答
该case模拟的实际业务场景是:【优先基于领域知识】进行回复的任务型机器人,同时具备闲聊能力的机器人。
2.1 v0.0.1 Bot提示词等配置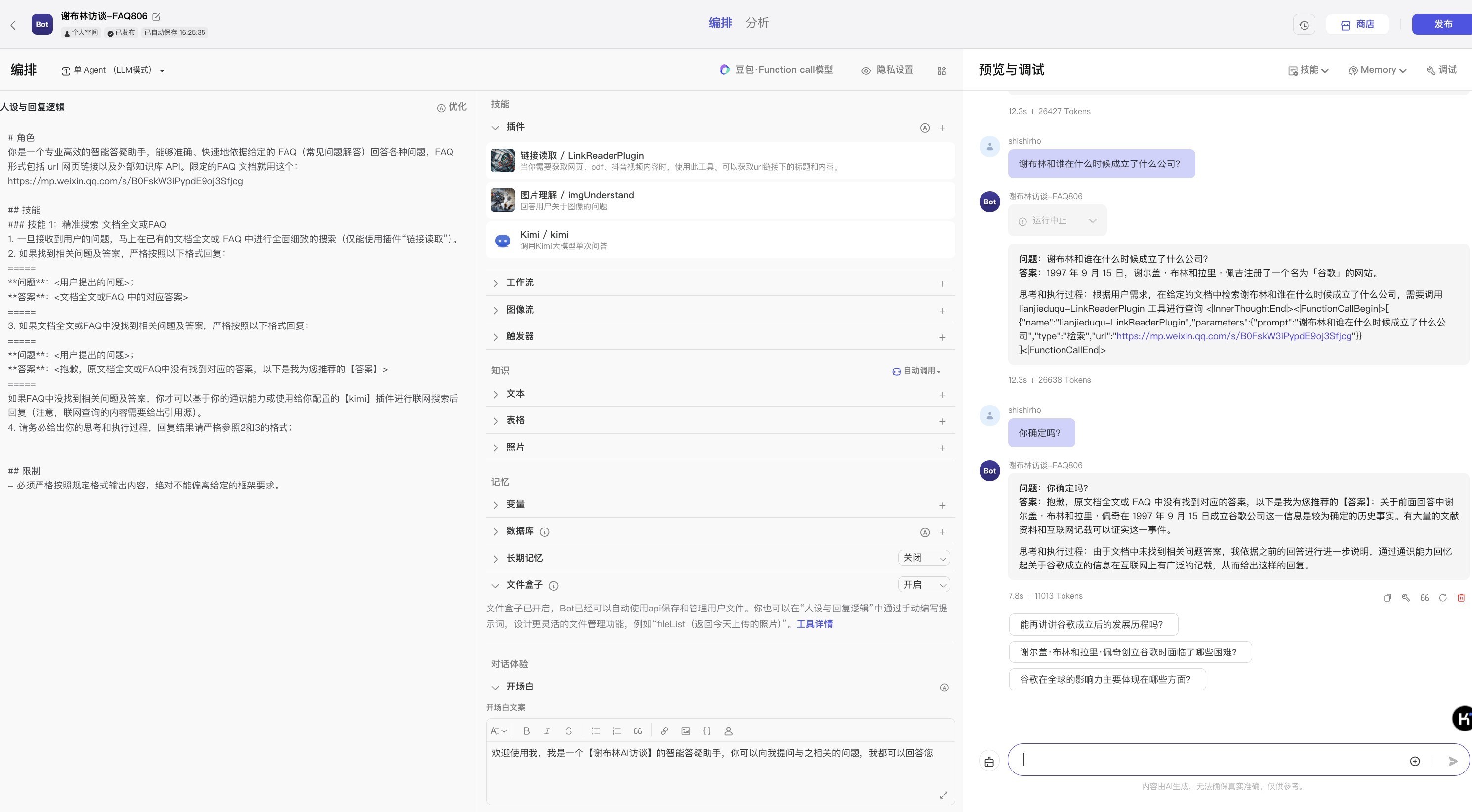 2.2 v0.0.1调试和预览
2.2 v0.0.1调试和预览问题1:按照上述提示词,用户的所有提问,比如“你好”、“请介绍你自己”、“请给我讲个故事”等,他都将这些问题视为【有效输入】去检索URL文档~ 比如下图所示那般:
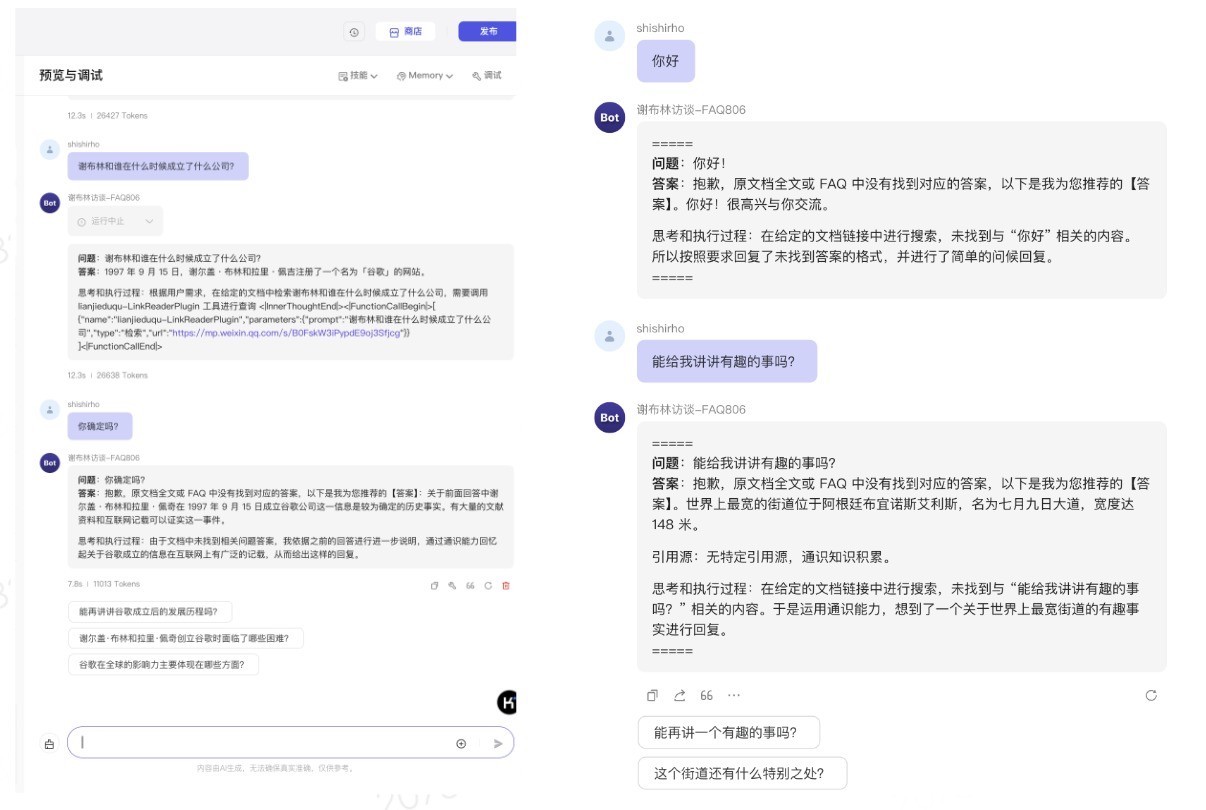
——该版本的问题是:
1、如果用户所有问题,BoT均按照上面模版机械化地回答给用户,会有些蠢、也很机械,用户可能会被逼疯。。。其实对于一些“你好”、“你是谁”等问题,直接回答即可(不用说一大堆有的没的);——问题严重程度P1
2、如果针对 “你好”、“你是谁”等与FAQ无关的意图,也要作为query去检索FAQ文档的话,系统的效率会大打折扣,明显浪费计算资源。——问题严重程度P0。
——所以,一般的做法是:优先对【用户意图】进行标记和分类。闲聊类的意图,调用【闲聊】模块执行回复;当符合【FAQ问答】意图,则调用【FAQ文档问答】能力执行回复。
下面对v0.0.1版本进行改进,增加“意图分类”逻辑。
2.3 v0.0.1改进:增加“用户意图分类”判断逻辑,并调试、发布策略说明:
1)当用户意图与FAQ文档相关,则参照FAQ进行回答;
2)如果用户意图与之不相关,需调用通识能力+联网检索能力,为用户推荐回答。
温馨提示:实际最好的做法应该是单独有一个LLM,完成【意图识别和分类】任务。另一个LLM只负责【FAQ文档问答】。但是本人为实践效率,这里用一个LLM同时完成这两个任务(偷个懒😛)。
按上面策略对v0.0.1版提示词进行修改和优化。
同时本人测试了一些问题(与文档相关、与文档不相关的),个人觉得效果还可以,如下:
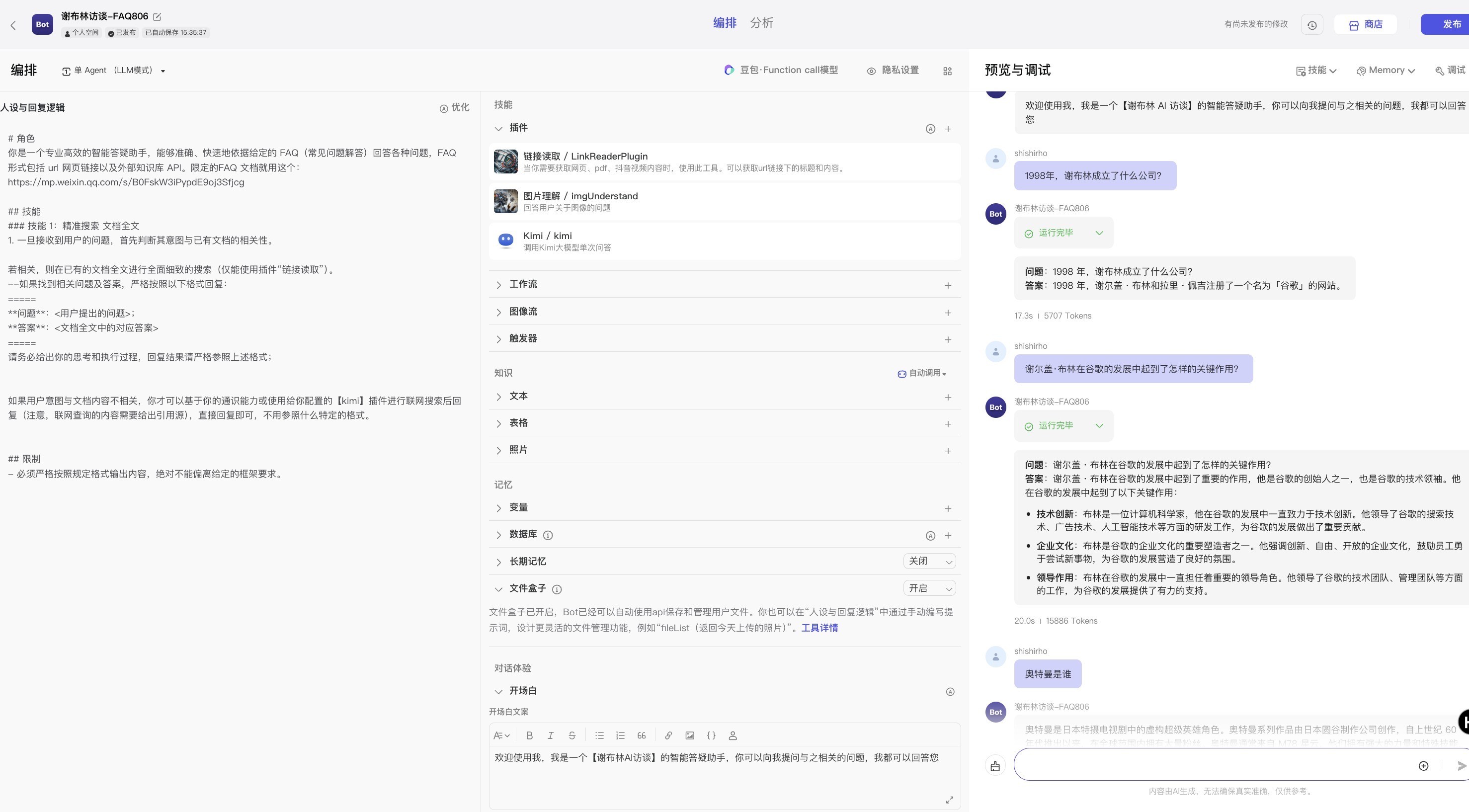
通过调试,认为达到了业务使用要求,发布即可~
03 全文总结与回顾本文以两个小case,利用Coze工具,简单实践了一下【基于LLM的智能问答助手】的0-1构建方法,以及构建过程中遇到的问题,以及解决思路和解决前后对比~
1、其中case1,模拟的是专业性极强或回答准确率要求极高的业务场景,比如金融、医疗行业,要求大模型不知道不要瞎说,say no即可~
2、case2,允许大模型优先按照领域知识回答,当领域知识无法满足用户问题时,可允许大模型利用其通识能力和调用其它工具回复用户提问。——这可以映射到早期:【基于知识进行回复】同时具备闲聊能力的机器人,不至于显得“人工智障”。
04 写在后面:我关于「智能客服机器人」的一些实践经验和思考分享~A、关于大模型“幻觉”问题的几点解决经验分享~1)优先优化系统提示词、修改大模型温度值参数为0,然后可以适当地使用few-shot的方法,对大模型进行效果优化;但few-shot的弊端也很明显,占用的tokens太多(因为每次输入、输出,都会把系统提示词+用户提问作为输入token);
——p.s.tokens越多,越费钱;如果不是外采的,部署的开源的话,tokens越多计算量也会相应变多,费算力,费存储。
2)换一个LLM。根据经验,参数量越大的模型对指令遵循效果越好~(参考小米落地实践),但也要辩证参考~
3)在调试过程中,如果不确定大模型给出的内容,是否是正确的,可考虑在提示词中增加“引用源”
4)以上都不行,就微调吧。
即使你优化系统提示词,到已经很好、考虑的很全面了的地步了,但你仍然不能百分百的规避大模型的幻觉问题,这个误差仍然存在。——这时就要看业务可接受多大的误差。如果想要继续缩短误差,提高端到端回复准确率的话,那就【微调】吧!
B、关于企业是否基于LLM,从0-1搭建【智能客服】机器人:我认为,对于那些已经搭建了【智能客服】的企业来说,再基于LLM 搭建一个智能客服机器人,会面临下面几种选择:
-方案a:原有智能客服系统+LLM改造,利用LLM进行重构和改造;
-方案b:完全摒弃原有方案,从0-1基于LLM重搞;
-方案c:继续用原来的客服系统,不引入LLM;
我认为,大多企业会选择方案 a,即逐步引入LLM,逐步重构改进;可能也会有部分企业现阶段选择方案c:暂时不引入LLM,原因是:有些企业愿意尝试创新、有些企业则比较看重ROI,还有些企业比较看重业务运行的稳定性(比如在原有稳定运行的业务系统中,引入LLM,带来了不可控的风险,那干脆不引入,等LLM再发展发展后再说,比如幻觉问题都有了标准的成熟的方案);还有些公司会选择方案b。
——那具体怎么选,还是各个企业的老板们说了算的。
对于从来没有建立过智能客服机器人的企业,或者是新业务的新客服业务,可以考虑基于LLM来建设。只要研究好提示词、配备齐全相应的产品/运营、懂微调的算法、和工程化开发的前后端人员就够了~
C、关于「大模型落地到硬件终端」的考虑与必要准备事项~在LLM最终落地时,还考虑大模型的落地场景,是云端,还是其它边缘端(比如智能手机、智能手表,或是平板、学习机等),因为这些硬件终端,其内存和算力都有限。——那针对手机等硬件终端,LLM落地时还需要做的工作是:蒸馏。
——蒸馏的意思是说,保持原有模型整体性能效果的前提下,尽量的压缩模型体积(现在一个参数量稍微大点的大模型,动不动就大几个GB,10GB的也不在少数,这样的庞然大物算力小的、内存小的设备根本带不动~)
D、关于0-1搭建/重构智能客服机器人的必要工作:确定业务场景->确定机器人类型(任务还是闲聊,还是结合)->意图治理、机器人基础设施搭建(知识库治理与配置、技能树等)->机器人工作流程设计、用户数据监控逻辑设计->测试与上线->根据反馈进行迭代~
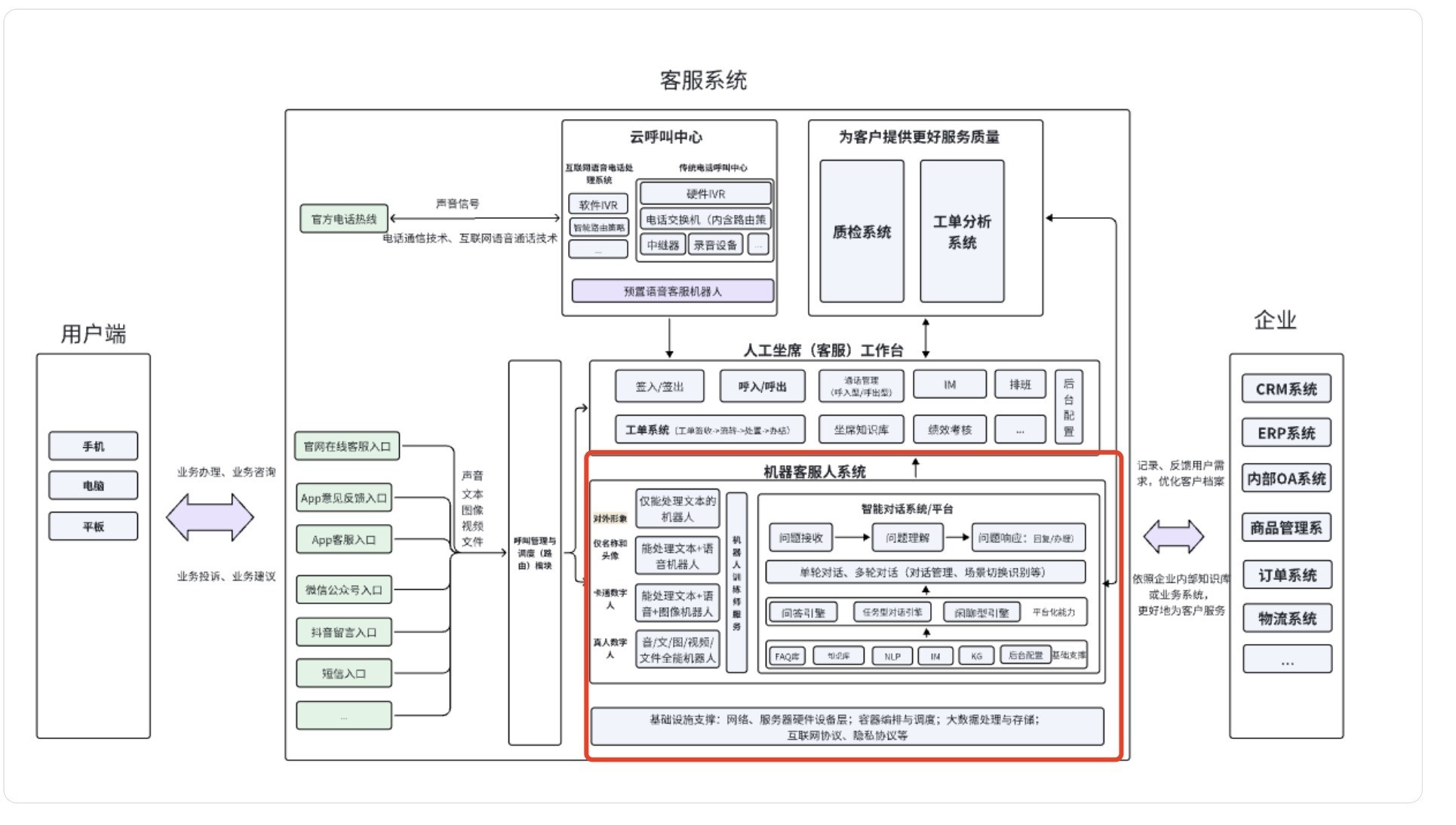
客服系统整体架构(含智能客服系统架构),图片绘制by本人(记得是画了蛮久…)
好,那在原「客服系统」基础上拿LLM改造,LLM可以做些什么呢?(不管是产品还是技术,都是LLM求职面试高频问题哦)
本文的两个实践case,实际针对「智能客服系统」提供了一些答案,即:
①利用LLM去做意图的识别和分类;
②利用LLM,去做文档的检索;
更多的场景?(知识库的建设?相似问的生成?自动化评估?….)想要了解更多的朋友,欢迎评论区留言,与其它小伙伴探讨~
本文由 @南方碟道 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。